El euskera es el idioma que tiene un mayor número de significados en Wikidata
Se encuentra en el sexto lugar en cuanto al número de lexemas
Ocupa el segundo puesto en cuanto al número de formas de las palabras
Es el principal idioma en cuanto al número de significados
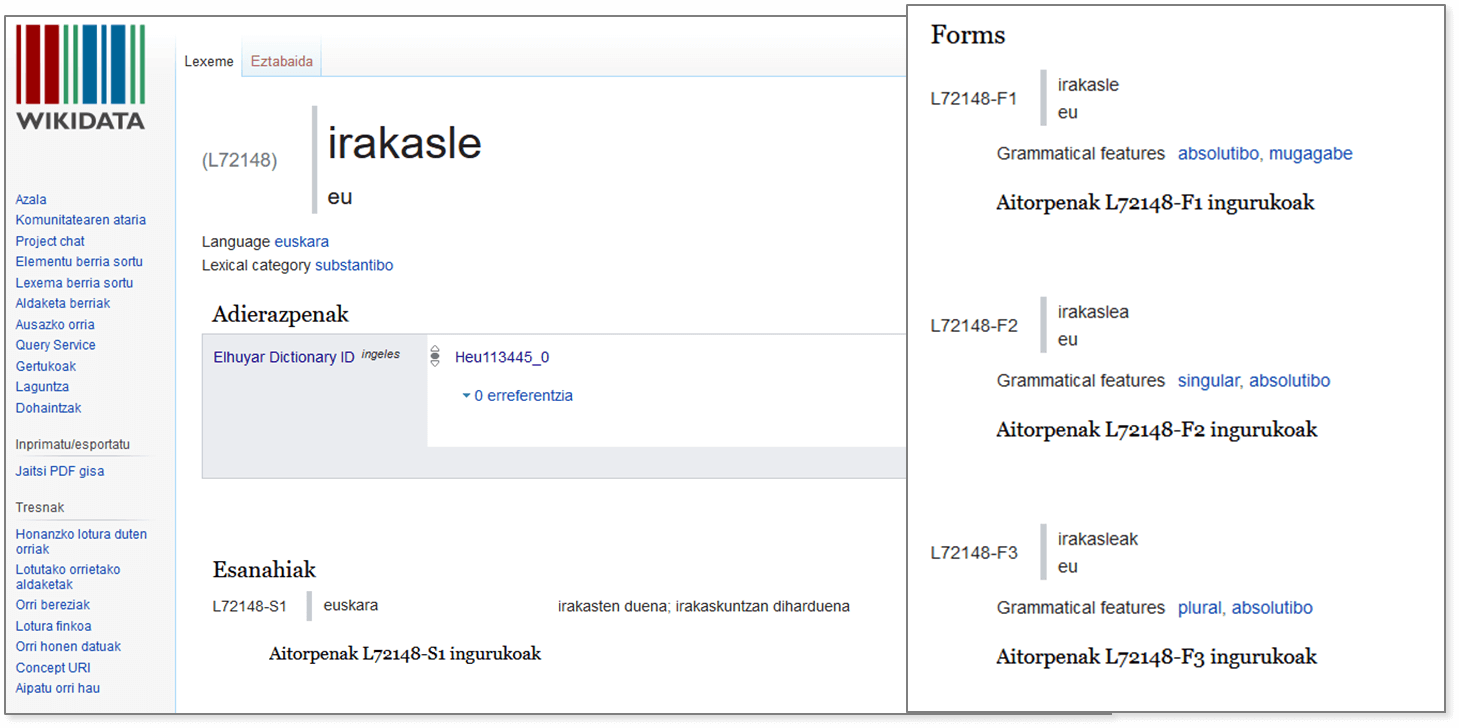
Gracias a la colaboración entre Euskal Wikilarien Kultur elkartea y Elhuyar, de entre todas las lenguas incluidas en Wikidata el euskera se encuentra en el sexto lugar en cuanto al número de lexemas, ocupa el segundo puesto en cuanto al número de formas de las palabras (teniendo en cuenta todas las formas que se crean al declinar cada lexema) y es el principal idioma en cuanto al número de significados, por delante del inglés, el castellano y el francés, entre otros.
Wikidata es una enorme base de datos que se edita de forma colaborativa. Lo gestiona la Fundación Wikimedia, con el fin de utilizarlo en sus proyectos; por ejemplo, en Wikipedia.
Se puso en marcha en 2012, y hemos ido alimentándolo progresivamente. Hace dos años, por ejemplo, incluimos alrededor de 6.500 conceptos provenientes del Diccionario Enciclopédico de la Ciencia y la Tecnología, así como varios vídeos de nuestro programa de televisión, Teknopolis.
A lo largo de estos últimos años, Wikidata ha comenzado a guardar nuevos tipos de datos, correspondientes a varios idiomas, en una estructura similar al de los diccionarios. Toda esta información se guarda clasificada en tres grupos: raíces de palabras (entradas de diccionario o lexemas), formas (las formas que puede tomar cada palabra en función del caso de declinación) y significados o definiciones.
Gracias a la colaboración entre Euskal Wikilariak Kultur Elkartea y Elhuyar, hemos podido incluir en Wikidata un gran número de palabras o lexemas (de la categoría de los sustantivos) de nuestro Ikaslearen Hiztegia, diccionario dirigido especialmente al alumnado. En total, se han añadido 10.000 lexemas, 65 formas de cada uno de estos lexemas (de todos los casos de declinación, en singular, plural e indeterminado) y sus definiciones.
Gracias a este trabajo, ahora resulta más fácil identificar las palabras en euskera, por ejemplo, en los textos de Wikipedia, y en un corto plazo se podrán desarrollar nuevas tecnologías a partir de estas bases de datos.
El código de programación desarrollado por el grupo de trabajo I+D de Elhuyar para este proyecto está disponible en GitHub.
Noticias relacionadas

ESGI 188 (European Study Group with Industry) se celebrará en Bilbao del 26 al 30 de mayo de 2025
Las empresas presentan problemas matemáticos para que los resuelva el grupo de estudio, a menudo en forma de problema de modelización u optimización.

MEPRO Medical Reproductive Solutions, tecnología con propósito: innovando en fertilidad masculina
“Nos mueve el compromiso de contribuir al sueño de la paternidad, mediante soluciones que mejoren la precisión, la eficacia y la accesibilidad de los tratamientos de fertilidad.”

Consulta abierta: tu oportunidad para definir los servicios de prevención laboral de Grupo Spri
Spri pone en marcha una consulta preliminar del mercado para diseñar una licitación ajustada a las necesidades reales del sector de la prevención de riesgos laborales y la vigilancia de la salud. Con ella, se busca recoger aportaciones de los operadores económicos para estructurar un proceso de contratación competitivo, transparente...

Aloka, una plataforma para alquiler de material audiovisual entre profesionales
La startup guipuzcoana ofrece distintos equipos como cámaras, grabadoras, micrófonos, drones. Participó en 4YFN del Mobile World Congress con un stand gestionado por Grupo SPRI para presentar la web a potenciales inversores y clientes.

Metagra, medio siglo de innovación en estampación en frío para automoción
La empresa de Bergara se ha consolidado en la fabricación de componentes complejos, apostando por la sostenibilidad y la innovación.

Impulsa la proyectos de innovación en tu empresa con Fast Track Innobideak
Abierta hasta el 20 de mayo, Fast Track Innobideak nace para impulsar y aumentar el número de empresas vascas innovadoras. Apoya actividades de innovación que introduzcan en el mercado nuevos bienes o servicios o que mejoren procesos de negocio en la empresa, que la hagan más competitiva.

Jon Ander Egaña: «BASQUE FOOD CLUSTER ha logrado posicionar la alimentación como un sector estratégico de la industria vasca»
La asociación vasca de cadena alimentaria trabaja para mejorar la competitividad de las más de 150 empresas y entidades asociadas con el desarrollo de la innovación, proyectos colaborativos y la integración de las tecnologías.

Siteco, 30 años dedicado a la fabricación de máquinas de cobro automático
La empresa alavesa trabaja con la Administración pública y el sector hostelero, y lleva años en el mercado internacional.

Mecanizados Patro aporta “fiabilidad, seguridad y eficiencia” al sector ferroviario
La firma alavesa fabrica piezas específicas tanto para series cortas como largas con herramientas y maquinaria de alta precisión.

Lorra, cerca de cuatro décadas como pilar fundamental del cooperativismo agroalimentario en Bizkaia
La prioridad de la entidad actualmente es suplir mediante el relevo generacional las jubilaciones en un sector envejecido.